All Activity
- Yesterday
-
Ok I will see if Wes can create me a section for ECN here.
-
sure go ahead its pretty much belongs to wes im dropping out of this so go ahead
-
Hi Chain! Hope all is well! I wanted to see about creating a space here somewhere for ECNChat. We previously used the IRCWx servers and system, but I have revamped the site and network to a custom built ircx server just for ECN. The network sponsors alot of the ole school MSN feels providing Chat, Groups, Messenger(Web and Desktop), and Arcade. We are currently in beta launch and testing everything. I would love a place here where I could advertise and post updates as well as post clients and scripts made for the network. Please let me know if that is possible.
- Earlier
-
🇩🇪 CODERS-IRC.NET – DAS IRC-NETZWERK FÜR CODER, SCRIPTER & TECH-FANS! 🚀 Du hast genug von überladenen Chat-Plattformen, Werbung, Tracking und geschlossenen Systemen? Dann wird es Zeit für echtes IRC! Willkommen bei Coders-IRC – einer modernen IRC-Community für Programmierer, Scripter, Webentwickler, IT-Profis, Radio-Moderatoren, Gamer und alle, die echte Live-Kommunikation schätzen. Das Netzwerk basiert auf moderner IRC-Technologie mit SSL-Sicherheit und aktiver Weiterentwicklung. 🌐 Website: Coders-IRC.net 💻 Warum Coders-IRC? ✅ Kostenlose Registrierung von Nicknames und Channels ✅ Sichere SSL/TLS-Verbindungen ✅ Moderne IRC-Server-Technologie (InspIRCd 4) ✅ Eigene Services und Verwaltungswerkzeuge ✅ Freundliche Community ✅ Unterstützung für mIRC, HexChat, KVIrc, AdiIRC und viele weitere Clients ✅ Eigene Spiele, Bots und IRC-Projekte ✅ Hilfe für Anfänger und erfahrene IRC-Nutzer ✅ Script- und Snippet-Sammlung für Entwickler ✅ Keine Datensammelei, keine Algorithmen, keine Werbung im Chat Coders-IRC entwickelt aktiv eigene IRC-Projekte wie "Pirate's Quest", CodeBreaker und zahlreiche IRC-Skripte und Ressourcen.
-
 chain changed their profile photo
chain changed their profile photo -
 MARVEL joined the community
MARVEL joined the community -
Quwqkibor joined the community
-
bogdomania joined the community
-
TiChou joined the community
-
REDman2k1 joined the community
-
tsme joined the community
-
V S joined the community
-
dannyx joined the community
-
Added a video to some some great features Recording 2026-03-03 100428.mp4
-
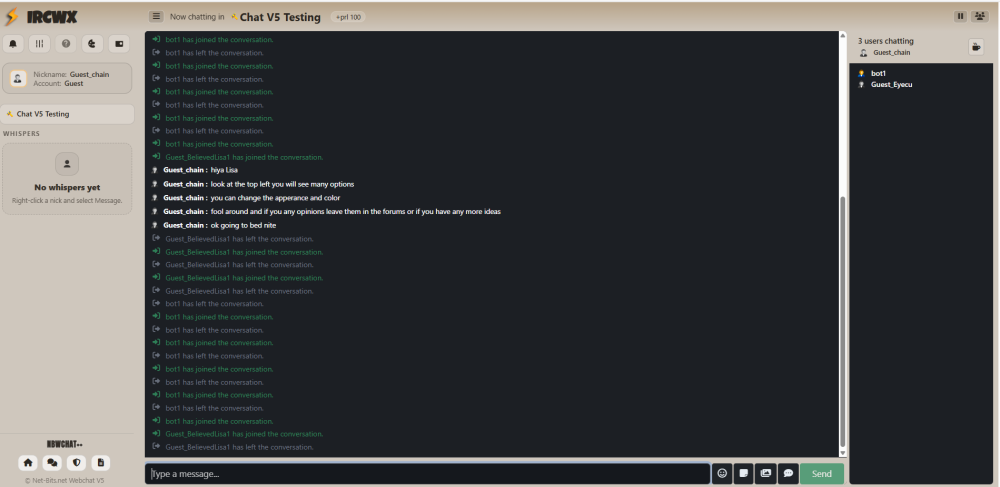
Buzzen V5 Webchat Development Announcement err0r is actively working on the Buzzen V5 Webchat to improve performance, usability, and overall chat experience. We welcome community feedback and feature suggestions. If there’s something you’d like to see added, improved, or changed, please share your ideas. Your input helps shape the future of the platform. Thank you for being part of the Buzzen community.
-
TripleXCrew joined the community
-
trashcan joined the community
-
; ============================================== ; Napa182's Updated By Chain 2025 FUNNY NICK FACTS – BUZZEN READY v3 ; NO INTERNET | NO SOCKETS | WORKS 100% ; ============================================== alias -l nfact { var %nick = $1 var %gender = $2 ; === MALE FACTS === if (%gender == m) { var %facts = secretly runs a underground fight club every Friday|was once banned from 3 zoos for feeding the animals pizza|has a PhD in meme theory|can solve a Rubik's cube in 7 seconds blindfolded|once arm-wrestled a bear and won|invented the word "yeet" in 2003|has a tattoo of his own nickname in Comic Sans|can quote every Star Wars movie backwards|sleeps with a nightlight shaped like a lightsaber|believes pineapple belongs on pizza and will die on that hill } ; === FEMALE FACTS === elseif (%gender == f) { var %facts = has a secret lair under her bed full of glitter bombs|can make any outfit look like it cost $10,000|once won a staring contest with a cat|runs a black market for cute stickers|can parallel park a tank|has a playlist for every mood, including "revenge"|taught her phone to say "yas queen" on command|owns 47 shades of lipstick and named them all|can silence a room just by raising one eyebrow|once beat a GPS at navigation } ; === OTHER / NON-BINARY / NEUTRAL === else { var %facts = communicates with squirrels using only clicks|has a pet rock named Kevin and takes it on vacation|can turn any argument into a rap battle|invented a dance move called "The Glitch"|runs on caffeine, chaos, and cosmic vibes|once hacked reality with a paperclip|believes in 7 impossible things before breakfast|has a backup personality just in case|can fold a fitted sheet in under 10 seconds|speaks fluent sarcasm and emoji } ; Pick random fact & replace $1 with nick var %fact = $gettok(%facts, $rand(1, $numtok(%facts, 124)), 124) return 10@nfact: 15 $+ %nick $+ $replace(%fact, $1, 15 $+ %nick $+ ) } ; ============================================== ; TRIGGER: @nfact Nick m/f/o ; ============================================== on $*:text:/^@nfact\s+(\S+)\s+([mfo])$/iS:#: { var %nick = $regml(1) var %gender = $lower($regml(2)) var %chan = # if (%nick ison %chan) { var %fact = $nfact(%nick, %gender) msg %chan %fact } else { notice $nick Sorry, 15 $+ %nick is not in 15 $+ %chan } } ; ============================================== ; LOAD MESSAGE ; ============================================== on *:load: { echo 12 -a 15Napa182'sUpdated By Chain Funny Nick Facts v3 4(INSTANT • OFFLINE • BUZZEN READY) echo 12 -a 14Type: @nfact YourNick m (or f/o) echo -a 14,1(14,1¯15,1¯0,1¯0,1º $+ $chr(171) $+ $chr(164) $+ $chr(88) $+ $chr(167) $+ $chr(199) $+ $chr(174) $+ $chr(238) $+ $chr(254) $+ $chr(116) $+ $chr(48) $+ $chr(174) $+ $chr(167) $+ $chr(88) $+ $chr(164) $+ $chr(187) º0,1¯15,1¯14,1¯) $+ $chr(153) }
-
This feeder was made for me and then i lost a file so had to learn err0r and i've updated it. efeeder.txt
-
Im a big fan of feeders so I decided to look at what a friend did for mine and learned to make more. I made it for Buzzen Displays what new in music and artists hope you have fun with it. emusicbot.txt